
Verilog与仿真工具
Verilog与仿真工具
Verilog建模
Verilog 模型可以描述实际电路中不同级别的抽象。所谓不同的抽象级别,是指同一个物理电路,可以在不同的层次上用 Verilog 语言来描述它。在这里,不同的层次可以理解为:电路的某个功能部件是由更小的、功能较为简单的部件连接组合而成的,因此可以将不同的部件划分在不同的层次。使用硬件描述语言(HDL)对系统进行抽象,可以在不同层次观察系统。类似于 C 语言当中,函数调用是对一组表达式集合的抽象。我们将着重于硬件设计的两类仿真级别:结构级建模以及行为级建模。
结构级建模和行为级建模是一对相辅相成的关系。在电路中,我们既需要对某一模块(部件)的行为、功能进行描述,也要在已设计好的模块之间进行连接,完成上层结构的建模。进一步讲,其又可以作为新的功能模块,供更上层的结构建模中使用,以此类推。
在进行电路刻画时,可用原理图(Schematic)进行表示。原理图通常包括器件(components)以及连线(wires),其中连线用于连接各器件。原理图具有输入输出,因此原理图描述的电路本身也可以作为器件使用,从而易于层次化设计。
使用 Verilog 语言进行结构级建模时,可将原理图中器件及连线映射为相应的语言描述要素,从而完成建模。该层次建模描述使用低层次器件(如常见简单门电路)描述模块(module),同时使用连线描述系统内各模块输入输出间的关系。
行为级建模则着力于==使用系统输出及输入的作用关系==。
同一个电路可以在上述两种级别分别进行建模。一般来讲,完成复杂电路的设计往往需要两种级别建模方式的参与。
复杂数字逻辑电路和系统的层次化、结构化设计意味着硬件设计方案的逐次分解。在设计过程的任意层次,硬件至少有一种描述建模形式。在集成电路设计的一层中,硬件可分解为一些模块(基本单元),这一层的硬件结构由这些模块的互连进行描述,该层次的硬件行为则由这些模块的行为描述。其中,基本单元可由下一层的基本单元互连而成。如此,完整的硬件设计可以由一棵倒置的设计树进行描述。在这棵设计树上,节点对应基本单元的描述,枝干对应于单元结构分解。
常用的硬件系统设计方法主要分为==自顶向下设计==以及==自底向上设计==两种:
在自顶向下设计(Top-down design)当中,从顶层开始,进行功能划分和结构设计,重写行为建模至结构建模,直到可使用元件/原语(primitive)进行描述;
从底向上设计(Bottom-up design)当中,从简单门器件出发(通常复用已制造的标准基本单元模块),逐层搭建更复杂的模块,直到实现顶层行为要求。
更进一步,电路的完整 Verilog HDL 模型是由若干个 Verilog HDL 模块构成的,每一个模块又可以由若干个子模块构成。这些模块可以分别用不同抽象级别的 Verilog HDL 描述,在一个模块中也可以有多种级别的描述。利用 Verilog HDL 语言结构所提供的这种功能就可以构造一个模块间的清晰层次结构来描述极其复杂的大型设计。
结构级建模
结构化建模就是把基本门和/或功能单元(主要是我们自己定义的模块)连接起来,从而产生特定的功能元件。结构化建模的过程,类似于我们在 Logisim 中连接一个电路, Logisim 为我们封装好了不同的模块,我们需要完成的只是对不同模块的连接。
在 Verilog 中,结构化建模的主要表现形式为实例化(instantiate)。通俗来讲,实例化就是利用某个模板所创建一个其所对应的实体的过程。我们想要使用一个元件前,需要对其进行实例化。在实例化的同时,我们需要指定模块输入输出端口与对应的信号。
对电路元件进行实例化的最常见语法是:
1 | |
其中,端口信号映射的格式也有两种:
- 位置映射:
模块名 实例名(信号1, 信号2, ...),其中信号 n 对应被实例化模块声明时排在第 n 位的端口。 - 名映射:
模块名 实例名(.端口名a(信号1), .端口名b(信号2), ...),其中信号 n 对应其前的端口名。
值得注意的是,在实例化元件时,wire 类型信号可以被连接至任意端口上,但 reg 类型的信号只能被连接至元件的输入端口上。在声明元件时,我们可以将任意端口声明为 wire 类型,但只能将==输出端口声明为 reg 类型==,否则会出现问题。
Verilog 中已经为我们预备好了一系列基本功能元件,称为==原语==,主要包括:
and, nand, or, nor, xor, xnor 这些 n 输入原语和 not 这一 n 输出原语
n 输入原语可以有多个输入,只能通过位置映射连接,对应端口连接顺序为输出, 输入1, 输入2, 输入3, …
n 输出原语可以有多个输出,只能通过位置映射连接,对应端口连接顺序为输出1, 输出2, …, 输出n, 输入
下面来看一个例子:
1 | |
对应的电路图如下所示:

行为级描述
对于一个复杂电路来说门级电路结构看起来会相当复杂。而且,使用 Verilog 描述的电路,一般最终都需要转换出实物,而同样的逻辑门,在不同的实现工艺上成本也会不同。因此,利用门级电路的结构直接对一个模块进行描述时,可能就显得不够灵活。
为了解决这些问题我们可以用比较直观的行为级描述进行电路的设计。使用行为级描述设计电路时,我们主要描述电路输入信号和输出信号间的逻辑关系,关注电路“干什么”而不是“怎么做”。低层次内部结构和实现细节等的考虑,以及将其转化为物理电路的过程,都由有关软件自动完成。其中这一转化过程就叫**综合 (synthesis)**。
值得注意的是,Verilog 的行为级描述并不意味着我们可以“为所欲为”。正如上文所说,任何电路设计最终都要着眼于最终的实现。综合工具的能力是有限的,并不是所有的结构都可以被有效的转换成真实的电路结构。因此在编写代码时,我们也要注重自己编写的代码的可综合性,了解自己代码对应的真实电路。
行为级描述的方法一般有两种:
- 利用连续赋值语句
assign描述电路。 - 利用
initial结构、always结构和过程控制语句描述电路。
连续赋值语句 assign
一种很重要的行为级描述就是连续赋值语句,其常见形式为:
1 | |
其中 signal 必须是==wire==型数据,而 expression 则是由数据和运算符组成的表达式。
assign 语句的作用是将右侧表达式的值==持续性==的赋给左侧的信号,一般用于描述一个信号是如何由其他信号生成的。所谓持续性,指的是当右侧表达式中的变量发生变化时,左侧信号的值也会随之变化。
assign 语句非常适合简单的组合逻辑的描述,经常与三目运算符配合使用。一般来说,assign 语句综合出来的电路是右侧表达式化简后所对应的逻辑门组合。
过程控制语句与有关结构
一个电路的输出,可以由输入信号决定(此时为纯粹的组合逻辑电路),也可以由输入信号和电路当前的状态决定(此时电路一般为时序电路)。我们可以把电路的当前状态(如果有)和电路的输出抽象为一些变量。通过描述不同条件下对这些变量的变化规律来描述电路,这就是利用过程控制语句与有关结构进行的行为级描述。
上文所述的变量,其实就是 Verilog 中的 reg 类型数据。要注意的是,reg 类型数据只是一个变量,用途是方便我们的描述,并不一定对应一个真实电路中的寄存器。综合工具在综合时,会通过对整体结构的分析,来判断电路具体如何实现。
利用过程控制语句与有关结构进行的行为级描述时,我们要解决两个主要问题:
- 如何将变量和模块的输出建立起关系。
- 如何描述不同情况下各变量的变化规律。
变量和模块输出间的关系
一般可以采用两种方法将变量和模块的输出建立起联系:
- 采用
assign语句,将变量的值赋给输出信号(此时输出信号为wire型) - 直接将
output端口声明为reg型
变量变化规律的描述
我们采用过程控制语句对变量的变化进行描述。过程控制语句与我们学习过的 C 语言有一定相似,主要包括==阻塞/非阻塞==赋值语句、if/case 等条件语句以及各种循环语句。
过程控制语句不能直接存在于模块内,一般只能在 initial 或 always 结构中出现(还可以出现在任务和函数中,但是我们的实验基本上不会涉及)。一个模块中可以包含多个 initial 或 always 结构。多个 initial 或 always 结构中的语句会同时执行。
两种基本结构和语句块
initial 结构
initial 结构,形式为 initial 语句(块),从仿真 0 时刻开始执行其中的语句。在整个仿真过程中只执行一次,一般用于==初始化==某些变量的值。
always 结构
always 结构,形式为 always@(敏感条件列表) 语句(块),从==仿真 0 时刻开始执行==。
敏感条件列表一般由多个敏感条件之间用 or 连接形成。always 条件语句在敏感条件列表中有任一条件满足时被触发。
敏感条件主要分为两种:==边沿敏感和电平敏感==,一般不应混用。
边沿敏感条件的格式为 posedge/negedge 信号名,表明信号在处于上升沿/下降沿的时候会执行结构中的语句,一般用于时序逻辑的描述。
电平敏感条件的格式为信号名,表明该信号发生改变(注意不是为真)时会执行结构中的语句,一般用于组合逻辑的描述。
使用 always 结构描述组合逻辑时,可以使用 always@(*) 的简写,表示语句中所涉及到变量的任何变化都会引起该 always 结构的执行。
可省去 @(敏感条件列表),此时整个结构无条件执行,一次执行完毕后,立即重新开始执行。一般配合延迟语句在 testbench 的编写中使用,例如:always #5 clk = ~clk;
语句块
块语句的作用是将多条语句合并成一组,使它们像一条语句那样。在使用上一节提到的各种控制语句或者要使用 always/initial 过程块时,如果要执行多条语句,就可以使用块语句,这就类似于 C 语言中大括号里的语句。
块语句有两种:顺序块和并行块。顺序块的关键字是 begin - end,并行块的关键字是 fork - join,关键字位于块语句的起始位置和结束位置,相当于 C 语言中的左大括号和右大括号。块语句也可以嵌套。
从名字就可以看出这两种块的特点,顺序块中的语句是顺序执行的,而并行块中的语句是并行执行的。在我们的实验中只会用到顺序块,顺序块有以下特点:
- 顺序块中的语句是一条接一条按顺序执行的,只有前面的语句执行完成之后才能执行后面的语句,除非是带有内嵌延迟控制的非阻塞赋值语句。
- 如果语句包括延迟,那么延迟总是相对于前面那条语句执行完成的仿真时间的。
配合语句块使用,两种基本结构的格式就变为:
1 | |
常见的过程控制语句
i. if 语句
1 | |
ii. while 语句
1 | |
iii. for 语句
1 | |
其中,每个 statement 可能是阻塞赋值语句或非阻塞赋值语句。他们在仿真时具有不同的行为。
过程控制语句描述的一般用法
always 块实现组合逻辑的一般格式为:
1 | |
always块实现时序逻辑的一般格式为:
1 | |
注意:不要混用阻塞和非阻塞赋值,==尽量只在组合逻辑中使用阻塞赋值,只在时序逻辑中使用非阻塞赋值==。
ISE入门
输入输出设计
定义模块:工程管理视窗单击右键 -> New source -> Verilog Module
| Module Name | 模块名 |
|---|---|
| Port Name | 端口名 |
| Direction | 端口方向 |
| Bus | 不勾选表示该端口为一位信号,勾选表示该端口为多位信号 |
| MSB | 最高位 |
| LSB | 最低位 |
语言模板辅助工具
ISE 中内嵌的语言模板包括了大量的开发实例以及 FPGA 语法的介绍和举例。
- Verilog HDL / HDL 常用模块
- FPGA 原语使用实例
- 约束文件的语法规则
- 各类指令和符号的说明
语言模板不仅可在设计中直接使用,还是辅助 FPGA 开发的工具手册。
选择 Edit -> Language Templates 打开语言模板
语言模板的使用
$readmemh函数的参数依次是数据文件路径、目标寄存器、起始地址和终止地址,其中起始地址和终止地址是可选项,因此该语句有三种用法:$readmemh("<数据文件名>",<存储器名>); $readmemh("<数据文件名>",<存储器名>,<起始地址>);`` $readmemh("<数据文件名>",<存储器名>,<起始地址>,<终止地址>); 导入格式为十六进制形式。
$readmemb函数的用法类似,只不过导入的是二进制形式。
VCS入门
VCS与Verdi简介
VCS 是一款编译型的 Verilog 仿真器。它能够将 Verilog 像编译 C 语言程序那样编译成一个可执行文件,只需运行这个可执行文件,就能进行仿真。VCS 的编译与运行都是以命令行形式完成的。
Verdi 是一个调试平台。它能够查看 VCS 仿真程序的运行轨迹、波形,同时对仿真过程中的值来源、错误原因进行追踪和分析。
VCS项目结构
为了使 VCS 上手更加容易,我们准备了一个 VCS 工程示例文件,位于 ~/VCS-Example 文件夹中,(*~是一个缩写,代表用户的主目录(home),课程所用虚拟机中用户的主目录的路径为/home/co-eda。*)其内容如下图所示。在完成题目时,可直接将此示例工程复制,并在其基础上修改、完成你的设计。
本示例工程中,各个文件的作用列举如下。
1 | |
项目目录下,.sh 结尾的文件是==脚本文件==,用于执行一些==常用任务==;src 目录存放了==设计的源代码==和==Testbench==;sim 目录将存放编译好的==二进制文件==和运行时产生的==波形==。
编译项目
若要开始仿真,首先需要将 Verilog 源代码编译为可执行文件。在 VCS-Example 文件夹中打开终端,并输入 ./compile.sh,就可以编译项目了。执行命令后,会看到 VCS 的运行日志,如果编译成功,则输出类似这样:

运行 cat compile.sh 或用 Sublime Text 打开 compile.sh,即可查看这个脚本的代码。第一行为 Shebang;# 开头的行为注释;具有实际功能的是最后一行,其调用 vcs 命令进行编译,将 src 目录下的所有 .v 文件编译为 sim 文件夹下的 simv 文件。
1 | |
Verilog语法
模块的定义方法
模块(module)是 Verilog HDL 的基本功能单元,它实际上代表了具有一定功能的==电路实体==。通俗来讲,其代表了电路中被导线连接的各个功能模块(子电路)。
下面我们通过一个简单的==与门(&)==实例来说明模块定义的基本语法:(Verilog HDL 的注释方式与 C 语言相同)
法1:
1 | |
法2:
1 | |
两种方法没有实质上的区别,只是形式上有所不同:方法 1 对方法 2 中的端口定义及 IO 说明进行了==合并==。(定义略有差别)
从上面的例子可以看出,一个模块以==module==开始,以 ==endmodule== 结束,包括模块名、端口定义、I/O (input/output)说明、内部信号声明和功能定义等部分。需要指出的是,模块中的语句除了顺序块之外,都是“并行的”(==同时执行的==);输入输出端口若不特别说明类型及位宽,默认为 1 位 wire 型。
只有连续赋值语句assign和实例引用语句可以独立于过程块而存在于模块的功能定义部分。
在一个模块中改变另一个模块的参数时,需使用defparam命令。
常用数据类型
wire型
wire 型数据属于线网 nets 型数据(nets型变量不能储存值,必须受到驱动器(门、assign等)的驱动,若为驱动该变量就是高阻的,值为z),通常用于表示组合逻辑信号,可以将它类比为电路中的导线。它本身并不能存储数据,需要有输入才有输出(这里输入的专业术语叫驱动器),且输出随着输入的改变而即时改变。一般使用 assign 语句对 wire 型数据进行驱动。
wire 型的数据分为标量(1 位)和向量(多位)两种。可以在声明过程中使用范围指示器指明位数,如 wire [31:0] a;。冒号两侧分别代表最高有效位(MSB, Most Significant Bit)和最低有效位(LSB, Least Significant Bit)。在访问时,可以使用形如 a[7:4] (注意是:,而不是,)的方式取出 a 的第 7-4 位数据。
一般在使用 wire 型数据前应先声明它。但如果在模块实例的端口信号列表中使用了一个未声明的变量,则会将其默认定义为 1 位的 wire 变量。
需要注意的是,信号变量与 C 语言中的变量有所不同,不能像 C 语言一样随意赋值,一般需要按照组合逻辑的规则进行操作。比如,对于 wire 型变量 a,==assign a = a + 1是不合法的==。
wire 型数据类型不具有存储功能,它类比于电路中的导线,只能将信号直接相连,无法存储。
注意:
1.使用向量时,大小端顺序必须与声明时的顺序保持一致。声明时为[3:0] a,那么a[0:3]是错误的写法。
2.使用未经声明的变量不会导致错误。变量未经声明即使用时默认为 1 位 wire 型变量。
3.声明wire型向量:wire[num1:num2] a(其中num1,num2为整数常量),则num1,num2的值==可以是负数==,且==num1、num2中的较大值可在前也可在后==。
4.使用assign语句时,若左右两侧位宽不一致时,会对右侧变量进行扩展或截断,使之与左侧变量位宽相等。
5.wire 型变量不能在 always 块中被赋值,但reg型变量可以,可以再需要赋值时将wire型变量声明为reg类型,或另外声明reg的变量。
reg型
reg 型是寄存器数据类型,具有存储功能。它也分为标量和向量,类似 wire 型,可以类比前面的教程。一般在 always 块内使用 reg 型变量,通过赋值语句来改变寄存器中的值,其作用与改变触发器储存的值相当。为了确定何时进行赋值,我们经常需要用到各种控制结构,包括 while、for、switch 等,这与 C 语言中的做法十分相似。
需要注意的是,==reg 型变量不能使用 assign 赋值==。而且,reg 型并不一定被综合成寄存器,还有可能被综合成 RAM 一类的存储器,它也可和 always 关键字配合,建模组合逻辑。
reg型数据的默认初始值为不定值x。reg型数据可以被赋正值,也可被赋负值。但当一个reg型数据是一个表达式中的操作数时,其值将被当作是无符号值,即正值。
利用 reg 数据类型建模存储器
我们可以通过对 reg 型变量建立数组来对存储器建模,例如 reg [31:0] mem [0:1023];,其中前面的中括号内为位宽,后面的中括号内为存储器数量。这种写法在我们开始搭建CPU后会用到。
我们可以通过引用操作访问存储器型数据元素,类似于位选择操作,例如 mem[2] 就是访问 mem 中的第 3 个元素。
wire 数据类型和 reg 数据类型是 Verilog HDL 中最常用的两种数据类型,其含义与同学们之前接触的 C 语言中的数据有些不同。在这里,理解 Verilog HDL 的关键在于“站在硬件的角度”来看待程序的设计与运行。
需要注意的是,Verilog HDL 中==没有多维数组==。
memory型
memory型数据是通过扩展reg型数据的地址范围来生成的。格式如下:
reg [n-1:0] 存储器名[m-1:0];
或 reg [n-1:0] 存储器名[m:1];
其实就是reg型向量。其中reg [n-1:0]定义了存储器中每个存储单元的大小;而[m-1:0]/[m:1]则定义了存储器个数。
注意:一个n位的存储器和一个由n个一位存储器组成的存储器组是不同的:
1 | |
数字字面量
Verilog 中的数字字面量可以按二进制(b 或 B)、八进制(o 或 O)、十六进制(h 或 H)、十进制(d 或 D)表示。
数字的完整表达为 <位宽>'<进制><值>,如 10'd100。省略位宽时采用默认位宽(与机器有关,一般为 32 位),省略进制时默认为十进制,值部分可以用下划线分开提高可读性,如 16'b1010_1011_1111_1010。(
Verilog 中除了普通的数字以外,还有两个特殊的值:**x** 和 z。x 为不定值,当某一二进制位的值不能确定时出现,变量的默认初始值为 x。z 为高阻态,代表没有连接到有效输入上。对于位宽大于 1 的数据类型,**x 与 z 均可只在部分位上出现**。
注意:
1.数字字面量定义中'不能省略,位宽和进制可以省略,但是该进制下的数字不能超过位宽(二进制下)所能表示的最大值。例如:3’101是个错误的定义,因为进制省略,所以采用默认的十进制,而位宽为3,此位宽下十进制最大值为7<101,定义错误。
2.可以定义负数,但是负号得写在位宽位之前,例如:32’d-100×,-32‘d100✓。
3.数字中间可以用短横 _ 隔开, Verilog 语法规定短横只能出现在数字之间。例如:8’b_0011_1010×。
4.特殊值 x 和 z 可以出现在多位数字中的某几位。例如:4’b10x0 和 4’b101z 均符合规范。
integer型
integer 数据类型一般为 32 位,与 C 语言中的 int 类似,默认为有符号数,在我们的实验中主要用于 for 循环。
parameter 型
parameter 类型用于在编译时确认值的常量,通过形如 parameter 标识符 = 表达式; 的语句进行定义,如:parameter width = 8;。在实例化模块时,可通过参数传递改变在被引用模块实例中已定义的参数。parameter 虽然看起来可变,但它属于常量,在编译时会有一个确定的值。
parameter 可以用于在模块实例化时指定数据位宽等参数,便于在结构相似、位宽不同的模块之间实现代码复用。
1 | |
参数型常数经常用于定义==延迟时间==和==变量宽度==。在模块或实例引用时,可通过参数传递改变在被引用模块或实例中已定义的参数。
几个实例
1 | |
组合逻辑建模常用语法
assign 语句
assign 语句是==连续赋值==语句,是组合逻辑的建模利器,其作用是用一个信号来驱动另一个信号。如 assign a = b;,其中 a 为 wire 型(也可由位拼接得到,见运算符部分),b 是由数据和运算符组成的表达式。
assign 语句与 C 语言的赋值语句有所不同,这里==“驱动”的含义类似于电路的连接==,也就是说,a 的值时刻等于 b。这也解释了 assign a = a + 1; 这样的语句为什么是不合法的。由于这样的特性,**assign 语句不能在 always 和 initial 块中使用**。
assign 语句经常与三目运算符配合使用建模组合逻辑。一般来说,assign 语句综合出来的电路是右侧表达式化简后所对应的逻辑门组合。
注意:
1.reg 类型变量不可以被 assign;
2.未被驱动的 wire 型变量可以理解为一段没有连接任何信号的导线,它和其他导线相连是没有意义的。因此 assign w2=w1(假设w1未被驱动)是错误的定义。
3.assign 意味着左侧的信号值始终等于右侧,因此w1=w1|w1中令 w1 始终等于 w1 | w1 是错误的。
常用运算符
Verilog HDL 中有相当多的运算符都与 C 语言基本相同,如:
- 基本运算符:
+,-,*,/,%等 - 位运算符:
&,|,~,^,>>,<<等 - 逻辑运算符:
&&,||,!等 - 关系运算符:
>,<,>=,<=等 - 条件运算符(三目运算符):
? :
这些运算的运算规则与 C 语言相同,只是在操作数中出现了不定值 x 和高阻值 z 的话最终结果可能也是带 x 或 z 的。另外 Verilog 中没有自增、自减运算符。下面主要介绍其他与 C 不同的部分。
逻辑右移运算符
>>与算术右移运算符>>>它们的区别主要在于前者在最高位补 0(
>>),而后者在最高位补符号位(>>>)。注意:算术右移的运算可以通过
$signed($signed(a)>>>b)来表示a算术右移b位。相等比较运算符
==与===和!=与!====和!=可能由于不定值x和高阻值z的出现导致结果为不定值x,而===和!==的结果一定是确定的 0 或 1(x与z也参与比较)。阻塞赋值
=和非阻塞赋值<=不同于
assign语句,这两种赋值方式被称为==过程赋值==,通常出现在initial和always块中,为reg型变量赋值。这种赋值类似 C 语言中的赋值,不同于assign语句,赋值仅会在一个时刻执行。由于 Verilog 描述硬件的特性,Verilog程序内会有大量的并行,因而产生了这两种赋值方式。这里暂时只需记住一点:为了写出正确、可综合的程序,在描述时序逻辑时要使用非阻塞式赋值<=。位拼接运算符
{}这个运算符可以将几个信号的某些位拼接起来,例如
{a, b[3:0], w, 3'b101};;可以简化重复的表达式,如{4{w}}等价于{w,w,w,w};还可以嵌套,{b, {3{a, b}}}等价于{b, {a, b, a, b, a, b}},也就等价于{b, a, b, a, b, a, b}。注意:像
{b,{3{a,b}}}这样拼接操作里的3{a,b}外的{}是不能少的,就把3{a,b}看作是一个整体的话,是需要一个花括号来将这个整体囊括起来,否则会报错。当你将一个16位的数值放在位拼接运算符中,且想要将其放在结果的低位时,应确保在位拼接时指定这个16位数值是从低位开始的,若将16位数值放在高位,其会被0填充到32位,因为位拼接时,未指定位宽的部分会用0填充至最近的局部变量或常量的位宽,省流:**一般来说,在位拼接中不指明位宽的数是不合法的,
尽管ISE并不会报错**。例如:
1
2
3
4
5
6
7
8
9
10
11
12
13
14reg [15:0] imm;
reg [31:0] result;
//假设imm已被赋值
result = {{16{0}},imm};//正确的赋值,imm将被赋值至低位
result = {imm,{16{0}}};//错误的赋值,得到的result将是32位的0,这是因为imm后的{16{0}}会被自动补为32位将把imm给"挤出",这种看着觉得是imm放置在高位,低位置0,结果得到却会是32位0。
//解决方案:
//方案一:用一个常量zero存储16位0,将imm和zero按顺序拼接在一起,即可得到相应结果
parameter [15:0] zero = 16'b0;
result = {imm,zero};
//方案二:先将imm放置在低16位,再通过左移16位得到imm置高位的结果
result = ({{16{0}},imm} << 16);
//方案三:表明低位0的具体位数,避免其自动扩展
result = {imm,16'b0};==缩减==运算符
运算符
&(与)、|(或)、^(异或)等作为单目运算符是对操作数的每一位(从低位向高位逐步运算)汇总运算,如对于reg[31:0] B;中的B来说,&B代表将B的每一位与起来得到的结果。
注意:
1.同一变量不能有多个 driver, 即==不能==被多次赋值。
常用实现方式:
assign赋值语句。always+ 阻塞赋值语句。建议尽量使用
assign赋值语句的方法实现组合逻辑,只有在必要场景下才使用后者:assign赋值语句的结构清晰:结合三目运算符的多层嵌套调用可以非常简洁地实现对应的组合逻辑。assign方式实现ALU标程:
1
2
3
4
5
6
7
8
9
10
11
12
13module ALU{
input [3:0] inA,
input [3:0] inB,
input [1:0] op,
output [3:0] ans
};
assign ans=(op==2'b00)?inA+inB:
(op==2'b01)?inA-inB:
(op==2'b10)?inA|inB:
(op==2'b11)?inA&inB:
4'b0000;
//assign只能对wire型变量赋值,不能对reg型变量赋值
endmodulealways+ 阻塞赋值的实现方法容易产生混淆:方法容易与实现时序逻辑的非阻塞赋值混淆从而埋下问题,且实现的语句更为复杂。always` + 阻塞赋值的实现方法实现ALU标程:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26module ALU{
input [3:0] inA,
input [3:0] inB,
input [1:0] op,
output reg [3:0] ans
};
always @(*)begin
case(op)
2'b00:begin
ans=inA+inB;
end
2'b01:begin
ans=inA-inB;
end
2'b10:begin
ans=inA|inB;
end
2'b11:begin
ans=inA&inB;
end
default:begin
ans=4'b0000;
end
endcase
end
endmodule3.在不考虑综合后==时序开销==的情况下尽量用
assign+ 三目的形式实现组合逻辑,从而保持always代码块中仅有非阻塞赋值语句。在考虑到时序开销的情况下(计组课设不对时序开销有任何严格约束),可以使用形如assign result = (is_A & A) | (is_B & B);的形式将连续三目表达式转换为并行的 MUX。
时序逻辑建模常用语法
always 块
always 块有如下两种用法:
- 若
always之后紧跟@(...),其中括号内是==敏感条件==(触发条件)列表,表示当括号中的条件满足时,将会执行always之后紧跟的语句或顺序语句块(和 C 语言中的语句块类似,只是将大括号用begin和end替换了)。这种用法主要用于建模时序逻辑。
举例如下:
1 | |
若
always之后紧跟 ==@ *== 或 ==@(*)==,则表示对其后紧跟的语句或语句块内所有信号的==变化敏感==。这种用法主要用于与reg型数据和阻塞赋值配合,建模组合逻辑。若
always紧跟语句,则表示在该语句执行完毕之后立刻再次执行。这种用法主要配合后面提到的时间控制语句使用,来产生一些周期性的信号。
always 的敏感条件列表中,条件使用变量名称表示,例如 always @(a) 表示当变量 a 发生变化时执行之后的语句;若条件前加上 posedge 关键字,如 always @(posedge a),表示当 a 达到上升沿,即从 0 变为 1 时触发条件,下降沿不触发;加上 negedge 则是下降沿触发条件,上升沿不触发。每个条件使用逗号 , 或 or 隔开,只要有其中一个条件被触发,always 之后的语句都会被执行。
为了良好的代码可读性与可综合性,不要在多个 always 块中对同一个变量进行赋值!
注意:
1.always 块既可以是边沿敏感的,也可以是电平敏感的,主要看敏感条件的书写。
2.==在多个 always 块中对同一个变量进行赋值的代码是不可综合的。==
3.指定端口位宽时,若形式为in[a : b],则两侧的数字均不能含有变量。正确的写法是采用如下的赋值形式:
assign out = in[sel * 4 +: 4];(采用[+:]表示位宽的方式)
指的一提的是,当端口位宽为 1 时,例如in[sel]的写法是允许的。(即本该写成in[sel +: 1]但允许写成in[sel]的形式。)
4.always块内的语句是按照书写的顺序执行的,称为“顺序语句”。
5.always块不能嵌套在initial块中。
initial 块
initial 块后面紧跟的语句或顺序语句块在硬件仿真开始时就会运行,且仅会运行==一次==,一般用于对 reg 型变量的取值进行==初始化==。initial 块通常仅用于仿真,是不可综合的。下面的代码用于给寄存器 a 赋初始值 0:
1 | |
if语句
Verilog 中 if 语句的语法和 C 语言基本相同,也有 else if、else 这样的用法。但是,if 语句只能出现在顺序块中,其后的分支也只能是语句或顺序块。举例如下(下面的例子也使用了 always 建模组合逻辑):
1 | |
为了避免意料之外的锁存器的生成而导致错误,建议为所有的 if 语句都写出相应的 else 分支。
case语句
Verilog 中的 case 语句与 C 语言的写法略有区别,详见下方的示例。case 语句同样只能出现在顺序块中,其中的分支也只能是语句或顺序块。与 C 语言不同,case 语句在分支执行结束后不会落入下一个分支,而会自动退出。举例如下:
1 | |
需要指出的是,case 语句进行的是全等比较,也就是每一位都相等(包括 x 和 z)才认为相等。另外,还有 casex 和 casez 两种语句。
其中casez可以实现priority encoder,
1 | |
例如上述代码可以实现4位的优先编码器,注意casez(会忽略z和?的比较)的匹配特性,第一个case内不满足才会跳到下一个。
这里的优先编码器是从低位到高位的第一个1。(!!!)
for语句
Verilog 中 for 语句的语法和 C 语言基本相同,但需要注意以下事项。
循环变量
integer 和 reg 类型的变量均可作为循环变量,使用 reg 类型变量作为循环变量时需要合理设置位宽,防止进入死循环状态。
以下为 reg 类型循环变量未合理设置位宽而造成的死循环示例代码(循环部分)
1 | |
仿真结果
1 | |
可以发现仿真进入死循环(Isim 也因此崩溃),不会输出 finish! 。这是因为循环变量 temp 是位宽为 2 的 reg 型变量,当循环计数到达 3 时,temp + 1 溢出,计数将再次从 0 开始,如此重复,不会出现 temp 大于 3 的情况,循环将一直被执行。
循环结束条件
建议写成类似
i < const形式(const表示常数),循环上限使用常数而非变量,否则容易造成死循环。需要使用输入信号的
for语句,比如输入信号限制最大值为31,建议写出类似i < inputA && i < 32形式,加上==常数限制==,避免可能的死循环。
for 语句对应实际线路
Verilog 中 for 语句在实际意义上并不等同于 C 语言中的,而是对应实际的线路。Verilog 作为一种硬件描述语言,建议==想好实际线路之后再写代码==。以下是一个 for 循环对应的线路示例。
1 | |
对应线路

for语句应用示例
下面给出使用 for 语句实现七人投票表决器的例子。
1 | |
while语句
Verilog 中 while 语句的语法和 C 语言基本相同。下面给出一个例子(对一个 8 位二进制数中值为 1 的位进行计数)
1 | |
注意:
1.在Verilog 中所有的循环语句只能在 always 或 initial 块中使用,因此 for 语句和 while 语句不能直接出现在语句块外。
2.循环语句中即可用==非阻塞赋值==,也可用==阻塞赋值==,所以 for 语句和 while 语句既可以用于建模组合逻辑(阻塞赋值),也可以用来建模时序逻辑(非阻塞赋值)。
时间控制语句
时间控制语句通常出现在测试模块中,用来产生符合我们期望变化的测试信号,比如每隔 5 个时间单位变更一次信号等。这个语句通过关键字 # 实现延时,格式为 **#时间**,当延时语句出现在顺序块中时它后面的语句会在延时完毕后继续执行。举例如下:
1 | |
常用实现方式
一般情况下:
1.(用宏定义对不同的状态表示进行简化)
2.初始化(采用initial块)
3.状态更新(采用always块)
4.输出更新(采用assign语句)
对于大部分的状态机,关键点在于寻找到所有的状态和正确的完整状态迁移,同时要处理好 always 的敏感变量。
模块的典型内部结构
一个模块的典型结构可以大致划分为三个部分:组合逻辑、时序逻辑和对其他模块的引用。
在组合逻辑部分,通常使用到的语法为 assign 语句,用于对 wire 型变量进行连续赋值。根据情况,我们也可能会使用 always 块来建模组合逻辑。
在时序逻辑部分,**always 块是必不可少的。通常我们会在 always 块中使用各种流程控制语句**建模时序逻辑。有时,我们还需要 initial 块对变量进行一定的初始化。
引用其他模块时,我们会用到模块实例化的语法(见Verilog建模中的结构级建模)。
阻塞赋值与非阻塞赋值
先通过一段实例代码来介绍二者之间的区别
1 | |
非阻塞赋值语句
处在一个 always 块中的非阻塞赋值是在块结束时同时并发执行的。对于以上示例代码,clk 信号的上升沿到来时,b_non_blocked 就等于 a 的值,c_non_blocked 就等于原来 b_non_blocked 的值。代码对应的电路图如下图所示,其中用到两个触发器。

对于 ISim,在每一条非阻塞赋值执行前,仿真器“按下快门”保存下了在 <= 右边参与运算的变量值。在块结束进行赋值时,对于 <= 左边被赋值的变量,都是用“快照”中的值参与运算的。

阻塞赋值语句
阻塞赋值语句的执行是具有明确==顺序==关系的,在 begin - end 的顺序块中,当前一句阻塞赋值完成后(即 = 左边的变化为右边的值后),下一条阻塞赋值语句才会被继续执行。对于以上示例代码,clk 信号上升沿到来时,b_blocked 先取 a 的值,c_blocked 再取 b_blocked 的值(即等于 a)。代码对应的电路图如下图所示,只用了一个触发器来寄存 a 的值并输出给 b_blocked 和 c_blocked ,这大概不是设计者的初衷,同时在时序逻辑中的阻塞赋值可能是不可综合的,所以非常有必要思考好是否使用阻塞赋值。

阻塞赋值在 Isim 中的仿真波形如下图所示:

块语句
顺序块
特点:
1.块内的语句是按顺序执行的。
2.每条语句的延迟时间是相对于前一条语句的仿真时间而言的。
3.所有语句都执行完,程序控制流程才跳出该语句块。
格式
1 | |
并行块
特点:
1.块内语句是同时执行的,即程序流程控制一进入到该并行块,块内语句则开始同时并行的执行。
2.块内每条语句的延迟时间是相对于程序流程控制进入到块内的仿真时间的。
3.延时时间是用来给赋值语句提供执行时序的。
4.当按时间时序排序在最后的语句执行完后或一个disable语句执行时,程序流程控制跳出该语句块。
格式
1 | |
其实感觉用顺序块+非阻塞赋值也可以达到并行块的效果。
块名
块名存在的原因:
1.可在块内定义局部变量,即只在块内使用的变量。
2.可允许块被其他语句调用,如disable语句。
3.在Verilog语言中,所有的变量都是静态的,即所有的变量都只有一个唯一的存储地址,因此进入或跳出块并不影响存储在变量内的值。
因此,块名提供了一个在任何仿真时刻确认变量值的方法。
有符号数的处理方法
在 Verilog HDL 中,wire、reg 等数据类型默认都是无符号的。当你希望做符号数的操作时,你需要使用 **$signed()**。
例子引入:
一个比较器的例子:
1 | |
我们希望程序实现比较 a, b 大小的功能,若 a > b,res 输出 1,否则输出 0,下面通过以下代码进行测试。
1 | |
我们初始化 a = 4,b = 1,100ns 后 b 变为 -1。期望的结果是 res 始终为 1。(因为4>1且4>-1是毋庸置疑的吧?)下面是波形:

可以看到 100ns 后,res 输出变为了 0,与预期不符。其原因在于比较时 Verilog 将 a 和 b 都默认视为无符号数,-1 会被认为是 15(4'b1111)。
将比较代码修改为 assign res = $signed(a) > $signed(b);,程序即可达到预期结果。
值得一提的是,假如将比较代码修改为 assign res = a > $signed(b);,得到的结果也达不到预期效果。
在对无符号数和符号数同时操作时,Verilog 会自动地做数据类型匹配,==将符号数向无符号数转化==。因为在执行 a > $signed(b) 时,a 是无符号数,$signed(b) 是符号数,Verilog 默认向无符号类型转化,得到的结果仍是无符号数的比较结果。
原理简介
Verilog 对于符号的处理有些特殊,分为最外层表达式符号的确定与向内传播两个过程。也就是说先确定下来最终结果有无符号,再向内传播进行类型转换,诸多诡异行为的“罪魁祸首”就是向内传播。
为了方便后续表述,让我们先定义两个概念。表达式和原子表达式,自决定表达式和上下文决定表达式。
注意,这些概念仅适用于本节。
概念定义
表达式和原子表达式。
单独的运算数(比如常数(32‘d1),变量(a))是表达式。
表达式与运算符的合法组合是表达式(a+1)。
设表达式 S 是表达式 A, B, … 与运算符X的合法组合。则称 A, B, … 是 S 的子表达式。
称没有子表达式的表达式为==原子表达式==(类比原子公式)。
1
2
3
4
5
6
7
8wire[1:0] a;
wire b;
32'd1 // 是表达式,常数
a // 是表达式,变量
a + 1 // 是表达式,加法运算
b ? a + 1 : a - 1 // 是表达式,三目运算
&a // 是表达式,单目与运算
&&a // 不是表达式,"&&"是双目运算符,不合法也不是表达式这里可以类比刚刚学习过的离散数学中对公式的定义,与我们这里对表达式的定义如出一辙,这将是以后常用的定义形式。另外,这里的原子代表不可再分,也是以后常会遇到的概念。
自决定表达式(self-determined expression)和上下文决定表达式(context-determined expression)。
自决定表达式的位宽和符号都是由自身决定的,和表达式所在的上下文无关。比如布尔表达式,不论它的子表达式和上下文如何,该表达式的结果总是一位的无符号数。
1 | |
上下文决定表达式的位宽和符号既由==自身==又由==上下文==决定。比如 a + $signed(b) 的例子。它的符号不由自身决定,它取决于其子表达式。
紧接着就来认识一下 Verilog 符号判定的两条原理——最外层表达式符号的确定和向内传播。
最外层表达式符号的确定
对于自决定表达式,它的符号由自身决定。
对于上下文决定的表达式,其符号和位宽和运算符无关,由其子表达式决定。确定规则可简单概括为,其子表达式中有任一表达式是无符号则该表达式就是无符号的。(一层一层向内”拨“)
那子表达式有无符号怎么确定?当做最外层表达式来判定。所以大家应该能理会到,表达式的符号确定规则是递归的规则。
举一个稍微复杂一点点的例子,$signed(a) * ($signed(b) + ($signed(c) - d))。这个表达式或许有些复杂,不过如果我们按上述定义提炼出它的树状结构,就可以更清晰地解读表达式。具体如图:

在该图中,非叶节点的符号都是无法确定的,只能依靠它的子节点确定。而其中,d 是无符号的,所以它的上层表达式也是无符号的。以至于最外层表达式也是无符号的。
向内传播
在用上述的规则确定好最外层表达式后,将最外层表达式的位宽和符号由外向内地传递给上下文决定的子表达式(自决定的子表达式不受影响)。这也是一个递归的过程,直至遇到原子表达式,此时要强制转换原子表达式的类型。
还是上面那个例子,在确定完最外层表达式是无符号的之后,原子表达式,就是树的叶节点,这些节点就都要强制转换为无符号的类型。所以最后上面的表达式的值等同于 a * (b + (c - d))。

一些特殊情况
看到这你可能会有疑问,在最开始的例子 a > $signed(b) 中,这应该是一个比较关系的布尔表达式,应该是自决定的,但是它仍然进行了向内传播。这是因为 Verilog 语言规定关系表达式与等式表达式属于自确定与上下文决定的中间态,具体体现为==结果是自确定的==,但是==它们的子表达式需要相互影响==。
对于移位运算符,其右侧的操作数总是被视为==无符号数==,并且不会对运算结果的符号性产生任何影响。结果的符号由运算符左侧的操作数和表达式的其余部分共同决定。
例子:
1 | |
Testbench部分内容如下所示:
1 | |
T1. 在101ns和103ns时,ans1的值分别为( A)。
A 4‘b0001;4’b0111 B 4’b0001;4’b1111 C 4’b1001;4’b0111 D 4’b1001;4’b1111
T2. 在101ns和103ns时,ans2的值分别为( B)。
A 4‘b0001;4’b0111 B 4’b0001;4’b1111 C 4’b1001;4’b0111 D 4’b1001;4’b1111
T3. 在101ns和103ns时,ans3的值分别为(A )。
A 4‘b0001;4’b0111 B 4’b0001;4’b1111 C 4’b1001;4’b0111 D 4’b1001;4’b1111
若运算子是否为有符号数对运算式的结果有影响,则应先通过==最外层表达式符号的确定==和==向内传播==两个原则来判断所有运算子的有无符号情况,再进行计算。
对于三目运算符,其 ?前的布尔表达式是自决定的表达式,不会对最外层表达式的符号造成影响。
总结
一、使用 $signed() 尽量使得运算数间有/无符号相同(移位运算是个例外),比如进行加法时,两个操作数都有符号,或者都没有符号,这样容易确定结果的符号。同时将 $signed() 用于较为简单的表达式,例如推荐下面的第一种写法而尽量避免第二种写法。第二种写法不仅可读性较差,还容易导致意想不到的问题。
1 | |
二、对于复杂的表达式避免使用 $signed() ,如果希望使用 $signed() 可以将这一部分抽离出来单独作为一个变量,比如
1 | |
三、如果你实在担心使用 $signed() 会出现意想不到的 bug,那么最简单的方式就是避开它。比如符号拓展可以写成如下
1 | |
四、最简单也是最重要的一点,当你不确定 $signed() 的行为时,不妨自行编写一个简单的testbench观察一下,通过观察结果可以直截了当地做出判断。
注意
1.在Verilog中负数在存储时会以补码的形式存储,但使用时仍会被看作是无符号数,使用有符号数表示==一定==要使用$signed()。
宏定义
类似 C 语言,Verilog HDL 也提供了编译预处理指令。下面对其中的宏定义部分作一简要介绍。
在 Verilog HDL 语言中,为了和一般的语句相区别,编译预处理命令**以符号 `(反引号,backtick)开头**(位于主键盘左上角,其对应的上键盘字符为 ~。注意这个符号不同于单引号)。这些预处理命令的有效作用范围为定义命令之后到本文结束或到其他命令定义替代该命令之处。
宏定义用一个指定的标识符(即名字)来代表一个字符串,它的一般形式为:``define 标识符(宏名) 字符串(宏内容)`。它的作用是指定用标识符来代替字符串,在编译预处理时,把程序中该命令以后所有的标识符都替换成字符串。举例如下:
1 | |
注意,**引用宏名时也必须在宏名前加上符号` **,以表明该名字是经过宏定义的名字。
注意
请不要滥用宏:编译器在编译时,会将宏“展开”(即替换)为对应的字符串。如果宏的内容较长,且展开次数较多(在代码中使用宏的次数较多),会带来较大的开销,导致仿真编译较慢,在线评测时可能会编译超时。因此,如果是希望定义类似“变量”的东西,在可以使用 wire 时,请使用 wire,而不是使用宏。
数据位宽 [+:] [-:]
+: 和-: 主要用来进行位宽度选择,语法如下:
reg [31:0] value;
value[base_express +: width_express];
其中base_express表示起始bit位置,width_express表示位宽。
例:
reg [15:0] big_value;
big_value[0+:8] (注意不是big_value[0+:7])等价于 big_value[7:0];
big_value[8+:8] (注意不是big_value[8+:7])等价于 big_value[15:8];
big_value[7-:8] (注意不是big_value[7-:7] )等价于 big_value[7:0];
big_value[15-:8](注意不是big_value[15-:7])等价于 big_value[15:8]。
Verilog工程的设计开发调试
不要用 initial 块、不要为寄存器赋初值
initial 块用于在仿真开始时对寄存器进行初始化、执行其他代码。在综合时,initial 块会被==忽略==,不起任何作用,且为 reg 指定的初始值也会被==忽略==。也就是说,如下的代码都是不起作用的。
1 | |
如果你想在模块开始运行时,对寄存器进行一些初始化,请使用 reset 信号控制复位,并在 Testbench 开始的部分提供一个 reset 信号。例如,上面的代码正确写法为:
1 | |
Testbench 正确的写法:
1 | |
一个寄存器只能在一个 always 块中赋值一次
Verilog 综合时,寄存器通常会被综合为 D 触发器(D-Flip-Flop)。通过之前的学习知道,D 触发器只有一个时钟输入、一个数据输入。因此,每个寄存器只能属于一个时钟域(“时钟域”指驱动触发器更新的时钟所表示的“范围”)。例如,以下代码会使 a 寄存器属于两个时钟域,因此是不可综合的:
1 | |
除了注意时钟域的归属外,我们也需保证在每个时钟周期中,寄存器被至多赋值一次,不能重复赋值。例如,以下的代码是不可综合的:
1 | |
需要注意的是“赋值一次”的含义。如果使用 if / else / case 语句进行条件判断,在不同且互斥的情况下对同一个寄存器进行赋值,是完全合法的。例如下面的代码:
1 | |
上述代码将被综合成如下硬件:

组合逻辑相关注意事项
我们一般会将代码分为“时序逻辑”和“组合逻辑”。时序逻辑使用 ==@(posedge clk)== 来表达,而组合逻辑使用 ==@(*)==来表达。在编写组合逻辑时,依照以下准则编写代码,可避免综合后产生奇怪的故障。
- 在时序逻辑中,永远使用非阻塞赋值(
<=);在组合逻辑中,永远使用阻塞赋值(=); - 每个组合逻辑运算结果仅在一个
always @(*)中修改; - 在
always @(*)中,为每个运算结果赋初值,避免 latch (锁存器)的产生。
一段实例代码如下:
1 | |
不要使用乘除法 - 用位运算来代替乘除法
FPGA 及 ASIC 硬件中,实现乘法和除法的代价是较高的,需要专门的乘法器、除法器,逻辑门的数量较多。在编写 Verilog 代码时,若非必要,则不要使用乘除法。
很多乘除法操作可以使用==移位或位拼接==来代替。移位运算在硬件中实现非常直接,使用的逻辑门数量也较少。使用位移运算代替乘除法的方法如下:
- 乘以2^n^:
- 左移 n 位,例如:
a * 8可替换为a << 3; - 在变量后面拼接 n 个 0,例如
a * 8可替换为{a, 3'b0}。
- 左移 n 位,例如:
- 除以2^n^:
- 右移 n 位,例如
a / 8可替换为a >> 3; - 取变量的高位,例如
a / 8可替换为a[7:3](若a一共有 8 位)。
- 右移 n 位,例如
- 求模 2^n^ - 取 n 位以后的低位,例如:
a % 8可以替换为a[2:0]。
在使用移位运算符时,请注意移位运算符的优先级问题。
Verilog代码规范
命名
VC-001 信号名称采用 snake_case,PascalCase 或者 camelCase
snake_case,即变量名全小写,单词之间用下划线分隔。PascalCase,即单词的首字母大写以区分单词。camelCase,即变量第一个单词小写,后续单词首字母大写。
例如:
1 | |
请统一整个程序的命名风格。
VC-002 信号极性为低有效用 _n 后缀表示
对于复位和使能信号,例如 rst 和 en,如果添加了 _n 后缀,表示值为 0 时生效(低有效,Active Low),值为 1 时不生效。
如果没有添加 _n 后缀,表示值为 1 时生效(高有效,Active High),值为 0 时不生效。详细解释见下面的表格:
| 信号名称 | 极性 | 1’b1 | 1’b0 |
|---|---|---|---|
| rst | 高有效 | 复位 | 不复位 |
| rst_n | 低有效 | 不复位 | 复位 |
| en | 高有效 | 写入 | 不写入 |
| en_n | 低有效 | 不写入 | 写入 |
当代码中需要混合使用 rst 和 rst_n 的时候,采用以下的方式来转换:
1 | |
VC-003 多路选择器标明规格
后续开发中可能会使用多种多路选择器,表明多路选择器的规格对于代码可读性有显著提升。 例如,4 选 32 位 1 的 MUX,模块的命名如下:
1 | |
VC-004 魔数(magic number)的命名
编写状态机的时候,各个状态一定要命名,之后调用的时候使用命名,而不是数字,减少代码中 magic number 的出现。建议使用 parameter,localparam 或者宏定义命名。 例如:
1 | |
如果仿真工具不支持在波形中显示为对应的状态名称,可以采用以下的方法:
1 | |
此时在仿真波形中,state_string 信号就可以看到状态的名称了。
另外,之后 P4 的学习,涉及到对指令的解析,也尽量使用宏定义等方式代替数字。 例如:
1 | |
组合逻辑的编写
VC-005 信号仅在一个 always 块中赋值
通常情况下,一个信号只会在一个 always 块中赋值。如果一个信号在多个 always 块中赋值,其结果是不可预测的。
VC-006 组合逻辑采用 always @(*) 块或者 assign 编写
组合逻辑的 always 块,使用以下的写法:
1 | |
VC-007 组合逻辑 always 块中仅使用阻塞赋值
表示组合逻辑的 always 块中所有的赋值请使用阻塞赋值(=)。使用非阻塞逻辑(<=)并不能模拟出实际组合逻辑的行为.
VC-008 组合逻辑 always 块中保证每个分支都进行赋值
如果组合逻辑中存在分支没有被赋值,那么实际综合中会综合出锁存器,FPGA 的底层基本组件并不存在锁存器,锁存器是使用查找表和寄存器组成,资源开销大。因此,如果使用了条件语句 if 或者 switch,需要保证信号在每个可能的分支途径下都进行了==赋值==,其中 switch 语句一定要写 default 分支,并对信号赋值
1 | |
另外,组合逻辑的 always 块中不要列举敏感信号。
1 | |
时序逻辑的编写
VC-009 时序逻辑在 always @(posedge clock) 中实现
当需要表示时序逻辑时,不能使用组合逻辑的写法,一定使用以下的写法:
1 | |
VC-010 时序逻辑 always 块中仅使用非阻塞赋值
时序逻辑 always 块中,所有的赋值请使用非阻塞赋值(<=)。
VC-011 不要使用下降沿触发,特殊协议除外
通常情况下,请不要使用下降沿触发:
1 | |
VC-012 不要使用非时钟 / 复位信号的边沿触发
通常情况下,不要使用除了时钟和复位以外的信号做边沿触发。
1 | |
VC-013 时序逻辑中不要使用时钟信号
在时序逻辑中,请不要在敏感列表以外的地方使用时钟信号:
1 | |
VC-014 使用同步复位,而不是异步复位
对于 FPGA,请使用同步复位,因为异步复位容易受到毛刺的影响。 代码如下:
1 | |
模块的编写和实例化
VC-015 不要在内部模块中使用 inout
FPGA 内部的模块之间请不要使用 inout,仿真环境除外。
VC-016 模块内部变量的定义和声明尽量统一
对于大模块的开发会使用大量的 wire 和 reg 变量,这些变量尽量统一在一个地方定义,后续增量开发在相应地方添加变量,而不是在需要使用的时候在旁边随手定义。另外,以免出现调用未声明变量的问题,可以添加宏定义 default_nettype。
1 | |
VC-017 模块的实例化多换行
后期开发中,一个模块可能有几十个端口。如果模块实例化的时候,端口挤在一起,可读性就会非常差,建议一个端口换一行,input 和 output 分开写,例如:
1 | |
代码风格
VC-018 符号两侧空格部分规则
- 单目运算符与变量间==不添加空格==,如
~、!。 - 双目运算符(除逗号外)和三目运算符两侧添加空格,如
+、=、<、&&。 - 分号和逗号要紧附前面内容,不应添加空格。
- 避免连续使用多个空格。
1 | |
VC-019 换行的使用
- 对于不同逻辑的代码块建议换行分开,并加上相应注释区分
- 对于同一逻辑,但是表达式复杂的语句,使用换行进行语义分割,如
1 | |
VC-020 模块缩进
对于对称的关键字,比如 begin & end,case & endcase ,jork-join等,采用缩进的方式对其进行优化对齐。
1 | |
VC-021 显式声明位宽
关于数据位宽有两点说明:
使用常数时,声明数据位宽,避免连线时出现位宽不一致的 Bug。
如果模块要使用数据的某一部分位,如
instruction[25:21],使用wire变量直接截取,重新赋予一个合理的命名,减少字面量以增强可读性。如:1
wire [5:1] piece = instruction[25:21]
VC-022 模块抽象
对重复使用的复杂代码进行抽象,而不是简单的复制粘贴。
综合工程的要求
一、前提
Verilog语法检测通过
二、
不使用==
initial==、fork、join、casex、casez、==延时语句(例如#10)==、==系统任务(例如$display)==等语句,具体可自行查阅学习。不与 x 和 z 值进行比较
用
always过程块描述组合逻辑时,应在敏感信号列表中列出所有的输入信号(或使用星号*)。用
always过程块描述时序逻辑时,敏感信号只能为时钟信号。所有的内部寄存器都应该能够被复位。
不能在一个以上的
always过程块中对同一个变量赋值。而对同一个赋值对象不能既使用阻塞式赋值,又使用非阻塞式赋值。尽量避免出现锁存器(latch),具体避免方法有许多。例如,如果不打算把变量推导成锁存器,那么必须在
if语句或case语句的所有条件分支中都对变量明确地赋值。避免混合使用上升沿和下降沿触发的触发器。
Pre_vvco_chanllenge
Verilog高级特性与自动化测试
编译预处理
可类比C语言中的#define等语句。
1.宏定义 ``define`
见时序逻辑建模常用语法中的宏定义。
2.文件包含``include`
所谓”文件包含”处理是一个源文件可以将另外一个源文件的全部内容包含进来,即将另外的文件包含到本文件之中。Verilog HDL 语言提供了 ``include` 命令用来实现”文件包含”的操作。其一般形式为:
1 | |
在编译的时候,需要对 ````include``` 命令进行”文件包含”预处理:将 File2.v 的全部内容复制插入到 ``include “File2.v”` 命令出现的地方,即将 File2.v 被包含到 File1.v 中。在接着往下进行编译中,将”包含”以后的 File1.v 作为一个源文件单位进行编译。
例如:
1 | |
在经过预处理后,counter.v将变成:
1 | |
四点说明:
一个 ````include``` 命令只能指定一个被包含的文件,如果要包含 n 个文件,要用 n 个 ``include` 命令。注意下面的写法是非法的:
1
`include "aaa.v""bbb.v"``include` 命令可以出现在 Verilog HDL 源程序的任何地方,被包含文件名可以是相对路径名,也可以是绝对路径名。例如:
1
`include "parts/count.v"可以将多个 ````include```命令写在一行,这一行除 ``include` 命令以外,只可以含有空格和单行注释。例如下面的写法是==合法==的:
1
`include "fileB" `include "fileC" // including fileB and fileC如果文件 1 包含文件 2,而文件 2 要用到文件 3 的内容,则可以在文件 1 用两个 ``include` 命令分别包含文件 2 和文件 3,而且文件 3 应出现在文件 2 之前。
补充:宏文件的引用
在具体代码实践中,我们定义的宏常常在多个文件中都需要使用。如果在每个文件中都采用复制粘贴的方式,那么在修改的时候就会有很大的工程量,所以我们常常单独开一个文件进行宏的定义,在其他文件中对这个“宏文件”进行引用。
1 | |
macro.v 是我们定义的一个“宏文件”,在其他需要使用到这个“宏文件”的文件头部,使用 ``include “macro.v”` 就可以使用“宏文件”中定义的宏了。
注意:不要 include 电路模块文件
在一个 .v 文件中使用其他 .v 文件定义的电路模块,请不要用 ``include` 命令包含模块定义的文件,而是将定义和使用模块的 .v 文件全部加入工程中,一起编译,否则在线评测时可能造成 “模块重复定义” 错误。一个反例如下:
1 | |
经过编译器的预处理(将文件 aaa.v 的内容复制到 bbb.v 中),文件 bbb.v 的完整内容为:
1 | |
评测机将 aaa.v 与 bbb.v 共同编译,模块 aaa 发生重复定义,导致编译错误。
只有在需要引用宏文件时才使用 ``include`。
3.`timescale
1 | |
例如:
1 | |
在这个命令之后,模块中所有的时间值都表示是 1ns 的整数倍。这是因为在 ````timescale``` 命令中,定义了时间单位是 1ns。模块中的延迟时间可表达为带3位小数的实型数,因为 ``timescale` 命令定义时间精度为 1ps。
4.条件编译命令 ````ifdef,else,elsif,endif,ifndef```
和 C 语言类似,这些条件编译编译指令用于包含 Verilog HDL 的可选行编译期间的源描述。 ```ifdef编译器指令检查 text_macro_name 的定义,如果定义了 text_macro_name,那么 ’ifdef 指令后面的行被包含在内。如果未定义 text_macro_name 并且存在 ‘else指令,则编译 else 后的源描述。(部分用‘代替)
’ifndef 编译器指令检查 text_macro_name 的定义。如果未定义 text_macro_name,则包含 ‘ifndef 指令后面的行。如果定义了 text_macro_name 并且存在’else 指令,则编译 ’else 后的源描述。如果 ‘elsif 指令存在(注意不是 ’else),编译器会检查 text_macro_name 的定义。如果定义存在,则包含 ``elsif 指令后面的行。(部分用‘代替)
’elseif 指令等同于编译器指令序列 ‘else ’ifdef …‘endif。该指令不需要相应的 ’endif指令。该指令必须以 ‘ifdef 或 ’ifndef 指令开头。(部分`用‘代替)
例如:
1 | |
大家可以充分利用条件编译指令来灵活控制自己的代码。
系统任务
Verilog 中还提供了很多系统任务,类似于 C 中的库函数,使用这些系统任务可以方便地进行测试。
输出信息
格式:$display(p1, p2, ..., pn);
这个系统任务的作用是用来输出信息,即将参数 p2 到 pn 按参数 p1 给定的格式输出。用法和 C 语言中的 printf 类似。下面用一个例子简单介绍其用法。
例如:
1 | |
其输出结果为: a = 10,b = 20
其中 %d 表示以十进制的形式输出,\n 为换行符。
在此说明几种常用的输出格式:
| 输出格式 | 说明 |
|---|---|
| %h 或 %H | 以十六进制数的形式输出 |
| %d 或 %D | 以十进制数的形式输出 |
| %b 或 %B | 以二进制数的形式输出 |
| %c 或 %C | 以 ASCII 码字符的形式输出 |
| %s 或 %S | 以字符串的形式输出 |
监控变量
格式:
$monitor(p1, p2, ..., pn);$monitor;$monitoron;$monitoroff;
任务 $monitor 提供了监控和输出参数列表中的表达式或变量值的功能。其参数列表中输出控制格式字符串和输出列表的规则和 $display 中的一样。当启动带有一个或多个参数的 $monitor 任务时,仿真器则建立一个处理机制,使得每当参数列表中变量或表达式的值发生变化时,整个参数列表中变量或表达式的值都将输出显示。如果同一时刻,两个或多个参数的值发生变化,则在该时刻只输出显示一次。
$monitoron 和 $monitoroff 任务的作用是通过打开和关闭监控标志来控制监控任务 $monitor 的启动和停止,这样使得程序员可以很容易地控制 $monitor 何时发生。其中 $monitoroff 任务用于关闭监控标志,停止监控任务 $monitor , $monitoron 则用于打开监控标志,启动 $monitor 监控任务。 $monitor 与 $display 的不同处还在于 $monitor 往往在 initial 块中调用,只要不调用 $monitoroff, $monitor 便不间断地对所设定的信号进行监视。
读取文件到存储器
格式:
$readmemh("<数据文件名>", <存储器名>);$readmemh("<数据文件名>", <存储器名>, <起始地址>);$readmemh("<数据文件名>", <存储器名>, <起始地址>, <结束地址>);
功能:
$readmemh 函数会根据绝对/相对路径找到需要访问的文件,按照 ASCII 的解码方式将文件字节流解码并读入容器。文件中的内容必须是十六进制数字 0~f 或是不定值 x,高阻值 z(字母大小写均可),不需要前导 0x,不同的数用空格或换行隔开。假设存储器名为 arr,起始地址为 s,结束地址为 d,那么文件中用空格隔开的数字会依次读入到 arr[s],arr[s+1]… 到 arr[d]。假如数字的位数大于数组元素的位数,那么只有低位会被读入,剩下的高位会被忽略。
此系统任务用来从文件中读取数据到存储器中,类似于 C 语言中的 fread 函数。
例如:
1 | |
仿真后即可将 code.txt 中的内容读入 im_reg 存储器中。
注意
表示存储器数量的中括号内的范围如果是从高到低的,例如 reg [31:0] img_reg [2047:0] ,则采用 $readmemh("<数据文件名>", <存储器名>, <起始地址>); 这种格式进行读入会在 ISE 和 VCS 上会得到不同的结果:在 ISE 中读入的数据从起始地址依次向低下标填充,而 VCS 中读入的数据从起始地址依次向高下标填充。
例如以下代码片段,读取文件后按下标顺序输出存储器的内容:
1 | |
数据文件 code.txt 内容为:
1 | |
这段代码在 ISE 和 VCS 中分别仿真会得到不同的结果,其中 ISE 仿真输出为:
1 | |
而 VCS 仿真输出为:
1 | |
要避免上述差异带来的影响,请按==从低到高==的范围声明存储器的数量,例如上述代码修改为 reg [7:0] mem [0:3] ;或在使用==从高到低==范围时显式给出 readmemh 的结束地址,例如 $readmemh("code.txt", mem, 1, 3) ,其中结束地址可以超过实际填充了数据的地址,只需大于起始地址。
层次化事件队列
由于Verilog 是硬件描述语言(HDL),语句的执行顺序与 C 语言程序有很大差异。层次化事件队列是硬件仿真(Simulation)时,用于规定“不同事件执行的优先级关系”,在这里我们可以一般将一个事件理解为需要运行的一条语句(当然,有的语句由多个事件组成,例如非阻塞赋值需要被拆分为计算等号右边的值(RHS)和将结果赋予等号的左边变量(LHS),赋值事件在计算事件执行结束时才能加入队列。根据事件的优先级,Verilog 将其分为 4 个队列(队列间的优先级不同,从上到下优先级依次递减,只有当优先级高的队列中所有任务完成后,才会继续完成优先级较低的任务)
动态事件队列(动态事件队列在队列内部执行顺序无硬性规定,但在同一个
begin-end语句块中的语句应当严格按照源代码中的顺序执行;且多个非阻塞赋值应当按照语句执行顺序进行)- 阻塞赋值
- 计算非阻塞赋值语句右边的表达式(RHS)
- 连续赋值(如
assign) - 执行
display命令 - ……
停止运行的时间队列(#0)(不推荐使用)
非阻塞事件队列:更新非阻塞赋值语句 LHS(左边变量)的值。
监控事件队列(执行
monitor,strobe命令)问题:
1.为何“阻塞与非阻塞的区别”视频教程的代码中,阻塞赋值与非阻塞赋值最终的结果存在不同(请对比两种赋值方式在更新等号左边变量操作(LHS)的优先级)?(因为阻塞赋值更新等号左边变量操作的优先级大于非阻塞赋值的,导致阻塞赋值中c同b同步被赋值为a的值,而非阻塞赋值中,c需要等一个周期才被赋为a的值。)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20module blocked_and_non_blocked(
input clk,
input a,
output reg b_blocked,
output reg c_blocked,
output reg b_non_blocked,
output reg c_non_blocked
);
// 阻塞赋值
always @(posedge clk) begin
b_blocked = a;
c_blocked = b_blocked;
end
// 非阻塞赋值
always @(posedge clk) begin
b_non_blocked <= a;
c_non_blocked <= b_non_blocked;
end
endmodule2.有时在
always语句块中,使用display、strobe、monitor三种输出语句会得到不同结果,这是为什么?(例如下面的代码,同一时刻的display和monitor所输出的值为何相差 1?)(因为优先级:执行display命令>LHS>执行monitor命令,所以在always块中,display命令输出的总是LHS之前的值,而monitor输出的则是LHS之后的值,又因为LHS执行后值加一,所以同一时刻的display和monitor输出的值相差1)。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15module display_monitor_diff(
input clk,
output reg [3:0] out
);
initial begin
out = 0;
$monitor($time,"monitor out = %d",out);
end
always @(posedge clk) begin
out <= out + 1;
$display($time,"display out = %d",out);
end
endmodule1
2
3
4
5
60 monitor out = 0
20 display out = 0
20 monitor out = 1
60 display out = 1
60 monitor out = 2
......3.在一个
always语句块中同时使用阻塞赋值与非阻塞赋值存在什么风险(提示:请结合同一事件队列中的任务顺序无硬性规定这一特点)?由这个结论,在书写语句块时应该遵循哪些规范?
`default nettype
1 | |
一些运算技巧
由于实际情况下,乘除运算单元的执行时间是其他单元执行时间的数倍,因此避免使用乘法和取模运算,使用位运算来代替。
乘法通过以下代码(c)实现:是一种类似小学乘法的过程,通过不同位的加法运算得到
1 | |
取模运算,这里特指对2的幂次数N的去模,也就是取一个数在N的二进制下1后面的数,通过N-1得到N上1后面所有位置1的情况,并同被取模数做按位与运算即可得到结果。
A%N=A&(N-1)
谨记
注意:运算符的优先级不是你想当然的,牢记加括号,加括号,加括号!!!!!!
写常数时标好位数和进制。
Verilog FSM 设计流程
设计流程
常用方法:always语句和case语句
一般步骤:
1.逻辑抽象,得到状态转换图
2.状态化简,可以将重复的状态化简成一个
3.状态编码,多种方式:Gray编码、独热编码等。实际电路中,需综合考虑电路复杂度与电路性能间的折中关系。不过,对于需在FPGA上运行的电路,推荐使用独热编码方式,因为FPGA有丰富的寄存器资源,门逻辑相对缺乏,使用独热编码可有效提高电路的速度和可靠性,同时提高器件的利用率。
采用独热编码的两种方式:parameter和`define语句:
1 | |
4.依据状态转移图得到次态逻辑和输出逻辑
5.按照相应逻辑,使用Verilog HDL描述有限状态机状态转移的情况:
- 复位方式(同步复位(在
always @(posedge clk)块中多加一个对于复位信号的特判)、异步复位(在always @(posedge clk)内多加一个对于异步复位信号的判断,与同步复位不同的是,同步是触发条件仍为时钟触发不变,而异步则触发条件需要改变,变为always @(posedge clk or posedge clr),clr为异步复位信号,在块内还需要多加一个对于该信号是否为1的特判,当其为1时,状态复原。由于or的判断属性其不为1是就为正常执行时钟触发时的条件。 - 用case或if-else语句描述出状态的转移(依据现态(和输入)产生次态,可与复位时回到起始状态的语句放在同一个
always块中,即敏感条件为时钟与复位信号) - 输出信号描述,采用case语句或if-else语句描述状态机的输出信号
设计建议
- 一般用case、casez、casex语句进行状态判断
- 在case语句最后一定要加上default分支语句,避免锁存器的产生
- 状态机一般应设计为同步方式,并由一个时钟信号触发
- 实用状态机都应设计为由唯一的时钟边沿触发的同步运行方式
- 从pre的challenge得来的血的教训:一定要多加括号,
除非你把运算符顺序背下来了;多采用模块化,不然代码行数过多,可读性很差;考虑情况要全面,某一个变量是否在多个状态下都需要进行处理。
generate块
生成块,可理解为复制。通常是对模块进行批量例化,或为有条件的例化,即使用参数进行控制对哪些模块进行例化或例化多少。除此之外,当一个操作或模块实例或用户定义原语或门级原语或连续赋值语句或initial和always块需要多次重复,或某些代码需根据给定的Verilog参数有条件地包含时,generate块将会很方便。
任务和函数的声明可出现在生成范围内,但不能出现在循环生成(generate-for)之中,它们同样具有唯一标识符名称,可以被层次引用。
不允许出现在生成范围中的模块项声明包括:1.参数、局部参数//可以使用,但不能声明;2.输入,输出和这二者的声明;3.指定块
generate for
用于批量处理某些赋值等行为,允许使用者对1.变量声明2.模块3.用户定义原语,门级原语4.连续赋值语句5. initial块和always块进行多次实例引用
例:
半加器模块:
1 | |
当我们需要多次进行加法时,设置一个可控制加法次数的模块
1 | |
testbench:
1 | |
使用时须先在genvar声明中声明循环中使用的索引变量名i,然后才能使用它。genvar声明的索引变量被用作整数用来判断generate循环。genvar声明可以是generate结构的内部或外部区域,并且相同的循环索引变量可以在多个generate循环中,只要这些环不嵌套。genvar只有在建模的时候才会出现,在仿真时就已经消失了。
生成快循环结构的本质就是用循环内的一条语句代替多条重复的Verilog代码,简化用户的编程
generate-if
允许有条件的调用(实例引用):1.模块;2.用户定义原语、门级原语;3.连续赋值语句;4. initial块和always块
基本结构:
1 | |
其从很多的备选块中选择至多一个,有可能一个也不选。建模中,条件必须为常量表达式。
条件if-generate不关心是否命名,并且可以不具有begin / end。当然,上述两个条件只能包含一项。它也会创建单独的范围和层次结构级别,这个和generate循环是一样的。由于最多选择一个代码块,因此在单个的if-generate中以相同的名称命名所有的备用代码块是合法的,而且这有助于保持对代码的分层引用。但是,不同的generate构造中必须具有不同的名称。
例:
1 | |
generate-case
用法类似基本case语句,可用于从几个块中有条件的选择一个代码块,相关规则同generate-if。
断言和形式验证
例:
如果有一个具有8个REQquest输入和8个ACK输出的仲裁器块,那么与其编写单个断言来覆盖所有8个REQ / ACK对,不如将其分解为具有1个REQ / ACK的8个独立断言每个声明对。
1 | |
层次化访问生成的模块
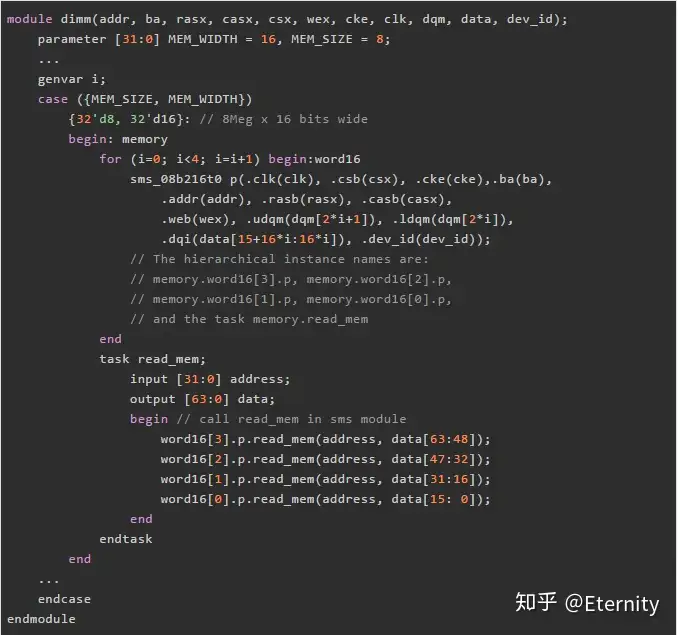
要访问generate块中的模块项,须使用
自动化测试的方法
在利用.prj和.tcl文件进行自动化测试时,不能在顶层模块里去``include其他非常量模块,不然会报illegal defination`的错误。
生成prj文件和tcl文件
prj 文件用于编译时说明工程包含哪些模块,往往包含工程目录中的 .v 文件(包括依据顶层模块的tesbench模块),格式如下:
1 | |
tcl 文件用于配置运行参数,如果需要运行 200us,则应包含以下内容:
1 | |
编译运行
在编译运行前,需要先设置环境变量,key 为 XILINX或者xilinx ,value 为 ISE 的安装路径,通常以 ise/14.7/ISE_DS/ISE/ 结尾。例如本机为:D:\ISE\14.7\ISE_DS\ISE.
若顶层模块名为mips.v,相应测试文件testbench为mips_tb.v,则编译命令如下(记得得在包含有mips.prj和testbench文件名的文件夹中打开终端),命令如下:
1 | |
若编译结果为mips.exe,(可能会出现各种问题,全面准备吧~),运行命令如下:
1 | |
此时可以使用管道(|)或重定向(<)保存输出信息,便于进行下一步的对拍。
采用cmd的dir指令和for指令,在进行编译前生成mips.prj
dir指令:显示目录中的文件和子目录列表。
DIR [drive:][path][filename] [/A[[:]attributes]] [/B] [/C] [/D] [/L] [/N]
[/O[[:]sortorder]] [/P] [/Q] [/R] [/S] [/T[[:]timefield]] [/W] [/X] [/4] (一般格式,其中的/A、/B等参数大小写均可)
其中[drive:][path][filename] 为指定要列出的驱动器、目录和/或文件。
/A 表示显示具有指定属性的文件。
属性 D 目录 R 只读文件
H 隐藏文件 A 准备存档的文件
S 系统文件 I 无内容索引文件
L 重新分析点 O 脱机文件
- 表示“否”的前缀
/B 表示使用空格式(没有标题信息或摘要)。
/C 在文件大小中显示千位数分隔符。这是默认值。用 /-C 来禁用分隔符显示。
/D 跟宽式相同,但文件是按栏分类列出的。
/L 用小写。
/N 新的长列表格式,其中文件名在最右边。
/O 用分类顺序列出文件。
排列顺序 N 按名称(字母顺序) S 按大小(从小到大)
E 按扩展名(字母顺序) D 按日期/时间(从先到后)
G 组目录优先 - 反转顺序的前缀
/P 在每个信息屏幕后暂停。(pause)
/Q 显示文件所有者。
/R 显示文件的备用数据流。
/S 显示指定目录和所有子目录中的文件
/T 控制显示或用来分类的时间字符域
时间段 C 创建时间
A 上次访问时间
W 上次写入的时间
/W 用宽列表格式。
/X 显示为非 8dot3 文件名产生的短名称。格式是 /N 的格式,短名称插在长名称前面。如果没有短名称,在其位置则显示空白。
/4 以四位数字显示年份
可以在 DIRCMD 环境变量中预先设定开关。通过添加前缀 - (破折号)
来替代预先设定的开关。例如,/-W。
for指令:对一组文件中的每一个文件执行某个特定命令。
一般格式:
1 | |
%variable :指定一个单一字母可替换的参数;
(set):指定一个或一组文件。可以使用通配符。
command: 指定对每个文件执行的命令。
command-parameters: 为特定命令指定参数或命令行开关。
1 | |
通过该方式可以在当前文件夹中新建一个写好./src/为相对路径的含有当前文件夹中所有.v文件的mip.prj文件(前提是mip.prj在写入前不存在,否则可能会出现覆写的情况)。
 微信
微信

